
Newly Developed Digital Device Turns Thoughts into Speech

The ability to speak and convey information to one another is one of humanity’s greatest gifts. Yet sometimes, words elude us. Phrases like “the word is on the tip of my tongue” embody the struggle everyone faces at times when thoughts cannot manifest themselves into spoken word. This tendency is especially common in people suffering neurological conditions characterized by speech impairment, such as amyotrophic lateral sclerosis (ALS). Developments in scientific technology make it possible, once again, for these people to communicate with less difficulty.
A recent study conducted by Columbia University explains the use of a new digital system that allows thoughts to be seamlessly translated into verbal speech. Previous results have only yielded garbled words that sound nothing like everyday speech (repetitive). But this new endeavor has managed to produce phrases that could be understood and repeated by human patients, an astounding accomplishment. How exactly did they do it?
In past studies, the traditional research route mainly focused on computer analysis of spectrograms, which are models used to visualize sound frequencies. Since every spoken sentence or listened phrase activates unique brain signals, neurological data could be corresponded to types of speech, in the same way that patterns of DNA in the Human Genome Project could be corresponded to certain genetic characteristics. However, because the technology used to scrutinize the spectrograms was too simple, scientists struggled to create an apparatus that could play back comprehensible audio.
Therefore, scientists had to refine the technology. Instead of relying upon spectrograms, the researchers employed a “vocoder”, a computer algorithm that can mimic speech after taking in many forms of auditory data. This parroting voice-recognition software is the same used to drive Apple’s Siri and Amazon’s Alexa. By feeding the algorithm with innumerable samples of speech from epilepsy patients, combined with the corresponding brain signals needed to produce them, the researchers made the system learn how to be the neural “middleman”.
This neural-net method is one of the fundamental aspects of artificial intelligence. It was modeled after the synapse-firing actions of neurons in the brain, allowing the program to receive new information and improve its protocols without external prompting. This design increased the program’s effectiveness in subsequent tests. Around 75% of the time, people could listen to and respond to what was being said by the system, an unprecedented result.
A recent study conducted by Columbia University explains the use of a new digital system that allows thoughts to be seamlessly translated into verbal speech. Previous results have only yielded garbled words that sound nothing like everyday speech (repetitive). But this new endeavor has managed to produce phrases that could be understood and repeated by human patients, an astounding accomplishment. How exactly did they do it?
In past studies, the traditional research route mainly focused on computer analysis of spectrograms, which are models used to visualize sound frequencies. Since every spoken sentence or listened phrase activates unique brain signals, neurological data could be corresponded to types of speech, in the same way that patterns of DNA in the Human Genome Project could be corresponded to certain genetic characteristics. However, because the technology used to scrutinize the spectrograms was too simple, scientists struggled to create an apparatus that could play back comprehensible audio.
Therefore, scientists had to refine the technology. Instead of relying upon spectrograms, the researchers employed a “vocoder”, a computer algorithm that can mimic speech after taking in many forms of auditory data. This parroting voice-recognition software is the same used to drive Apple’s Siri and Amazon’s Alexa. By feeding the algorithm with innumerable samples of speech from epilepsy patients, combined with the corresponding brain signals needed to produce them, the researchers made the system learn how to be the neural “middleman”.
This neural-net method is one of the fundamental aspects of artificial intelligence. It was modeled after the synapse-firing actions of neurons in the brain, allowing the program to receive new information and improve its protocols without external prompting. This design increased the program’s effectiveness in subsequent tests. Around 75% of the time, people could listen to and respond to what was being said by the system, an unprecedented result.
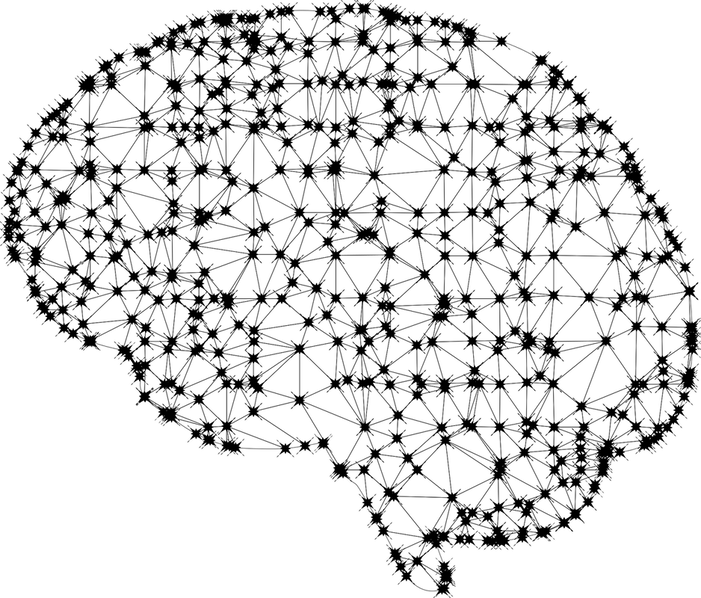
The “neural net” mimics the neurological network of a learning brain.
Image Source: GDJ
The implications of this breakthrough are novel and exciting. Patients stricken by muscular atrophy, neurological disorders like Parkinson’s or strokes could regain the ability to communicate with caretakers, reestablish relationships with family members, and become more active participants in face-to-face social interaction. In doing so, they are better able to reduce the negative effects of their disease, and overall gain more control over their lives.
Featured Image Source: Merio
RELATED ARTICLES
|
Vertical Divider

|
Vertical Divider
|
Vertical Divider
|
